Transforming LLMs into Powerful MultiModal Models
In the ever-evolving landscape of AI, there's a fascinating transformation happening right now: open-source Large Language Models (LLMs) are being extended with multi-modal capabilities, ushering in promising results. This outcome is two distinctive approaches, each offering its unique advantages. In this blog post, we'll delve into the two primary methodologies and explore their potential implications for the field of AI.
The Flamingo Approach: Gated Crossattention Layers
The first approch for extending an LLM with multi-modal capabilities, is based on the Flamingo architecture developed by DeepMind. The Flamingo model introduces a novel architecture that incorporates a separate vision encoder linked to the LLM through gated crossattention layers. The hidden states of the image encoder are merged with those of the LLM through multiple gated crossattention layers. This allows the model to undergo training on text data with interweaved images, ultimately giving rise to a multi-modal LLM with emerging capabilities.
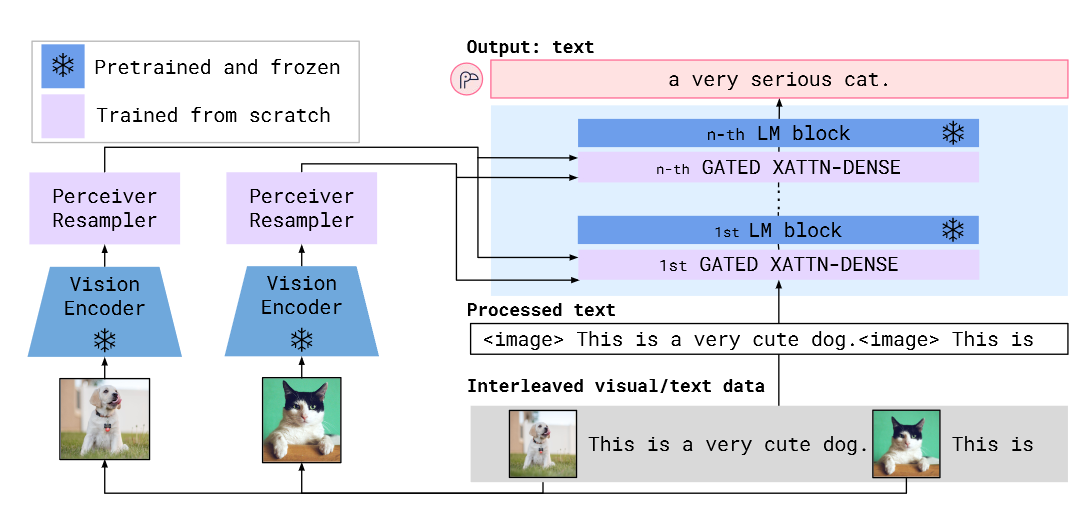
Figure 1: Flamingo Architecture from Flamingo: a Visual Language Model for Few-Shot Learning [1]
The LLaVA Approach: A Simple Yet Effective Solution
The secound approch is the LLaVA approach, which takes a more straightforward path, delivering equally promising results. Instead of altering the fundamental architecture of the LLM, this approach employs a straightforward linear layer to bridge the gap between the image encoder and the LLM. This linear layer projects image embeddings into token embeddings, which are then merged with the standard input tokens embeddings of the LLM. The result is a model that can be trained on multi-modal data, just like Flamingo, while maintaining a simpler structure.
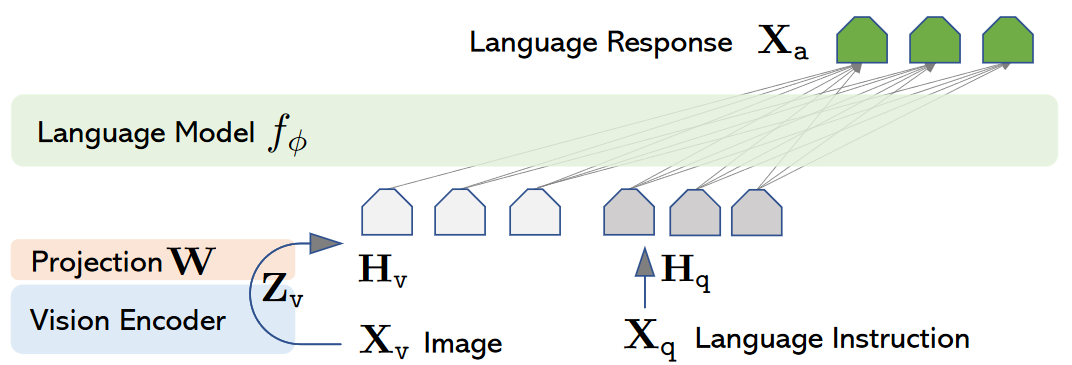
Figure 2: LLaVA Architecture from Visual Instruction Tuning [2]
Both of these approaches leverage the same image encoder model, known as Open-CLIP, which has been trained on billions of image-text pairs. This is the same model which has given rise to groundbreaking text-to-image models such as DALL-E and StableDiffusion.
CLIP: Unlocking the Power of Contrastive Learning
At the heart of this multi-modal transformation is CLIP, an acronym for Contrastive Language-Image Pre-Training. This model is trained with a contrastive loss function that seeks to maximize the cosine similarity between text embeddings and image embeddings. This contrastive approach is pivotal in enabling the model to bridge the semantic gap between language and images.
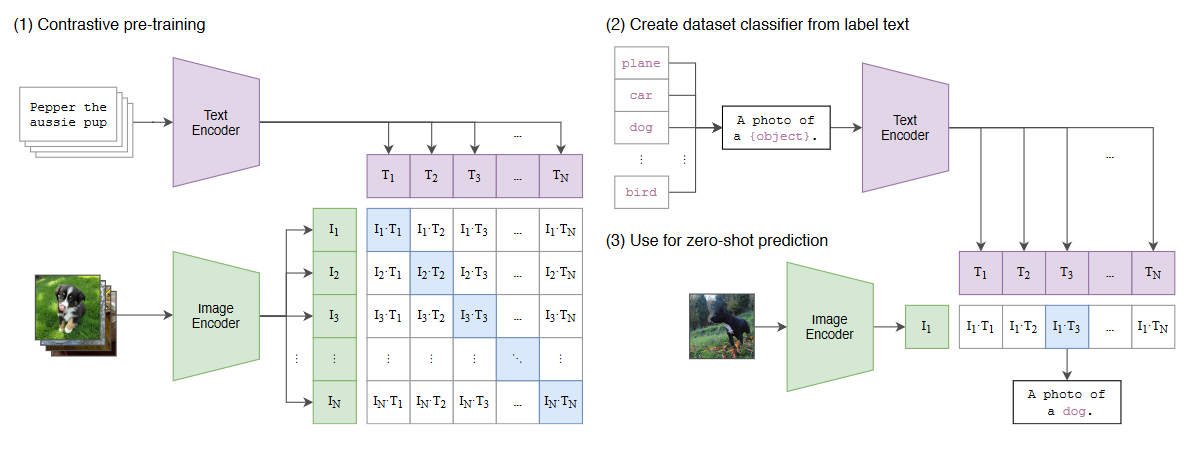
Figure 3: CLIP Approach from Learning Transferable Visual Models From Natural Language Supervision [3]
Enhancing Multi-Modal Models: Three Key Vectors
In the journey to enhance multi-modal models or any machine learning model, we identify three primary vectors of focus: compute, data, and architectures. These vectors, when individually or collectively improved, hold the potential to significantly boost the capabilities of machine learning models. As the famous adage goes, "The sum of the system is greater than its individual parts," emphasizing the critical importance of synergizing these vectors to push the boundaries of AI. In conclusion, extending LLMs with multi-modal capabilities is a pivotal step in the advancement of AI. The diverse approaches explored, including the intricacies of Flamingo and the simplicity of LLaVA, coupled with the foundation laid by CLIP, highlight the ever-evolving landscape of AI research. As we continue to refine these models, the possibilities are boundless, offering exciting prospects for the future of artificial intelligence.
References
[1] Jean-Baptiste Alayrac, Jeff Donahue Pauline Luc Antoine Miech Iain Barr† Yana Hasson† Karel Lenc† Arthur Mensch† Katie Millican† Malcolm Reynolds† Roman Ring† Eliza Rutherford† Serkan Cabi Tengda Han Zhitao Gong Sina Samangooei Marianne Monteiro Jacob Menick Sebastian Borgeaud Andrew Brock Aida Nematzadeh Sahand Sharifzadeh Mikolaj Binkowski Ricardo Barreira Oriol Vinyals Andrew Zisserman Karen Simonyan. Flamingo: a Visual Language Model for Few-Shot Learning, 2022
[2] Haotian Liu, Chunyuan Li, Qingyang Wu, Yong Jae Lee. Visual Instruction Tuning, 2023
[3] Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, Gretchen Krueger, Ilya Sutskever. Learning Transferable Visual Models From Natural Language Supervision, 2021